

Developer Productivity
Power up developer productivity and velocity
Dramatically reduce developer time spent on tedious and repetitive manual unit test writing, and watch engineering efficiency soar 🚀


Reduce time spent writing test code by 95% and get your developers back to doing what they love.
It’s the same old story – you need to have test cases in place to ensure code quality, but it would take years to write the tests you need by hand. Diffblue Cover’s AI autonomously writes Java unit tests, giving your development team more time to focus on achieving your delivery goals and more interesting work.
Get time back to work on business critical application code.
Developers typically spend between 20-50% of their time writing and updating unit tests. Automating test writing and maintenance means developers can spend the limited time they have dedicated to writing code, actually writing code.
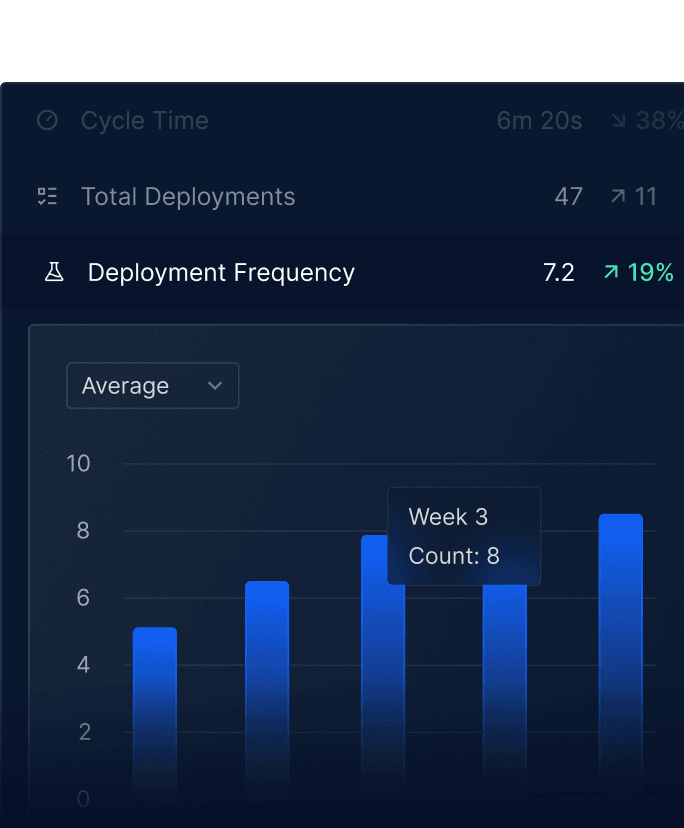
Effective unit testing is a powerful way to improve software delivery performance. But writing and maintaining comprehensive unit test suites for large applications takes considerable time and effort – time which doesn’t actually deliver the business value the DORA metrics are attempting to measure. Automate unit testing and improve team performance from day 1.
Improving developer experience has more business benefits than you think.

Unhappy developers will move on. The cost of attracting and retaining all star talent is huge, especially in markets with a tech labor shortage. Automating the mundane and tedious can help engineering teams stay happier for longer, and stay working for you for longer!
How Diffblue Cover helps drive developer productivity and velocity
Automates away manual test writing and maintenance
Cover operates at any scale, from method-level within your IDE to across an entire codebase as an integrated part of your automated Continuous Integration pipeline.
2. Enables teams to make progress towards DORA metrics
Save vast amounts of man hours spent manually writing tests, reach test coverage mandates quickly, and start to make actual progress towards critical measures.
3. Improves DevX and helps you retain developer talent.
Let AI do the testing, not your developers. Automate tedious tasks and reduce context switching to keep developers happy and motivated.


